-
[모두를 위한 딥러닝] 10-3. Dropout과 EnsembleAI/모두를 위한 딥러닝 2020. 12. 8. 15:40
# Overfitting 문제

뉴럴 넷의 가중치 변수를 많이 생성하고, 레이어를 깊게 쌓을수록 해당 모델은 training data에 오버피팅될 가능성이 높다. 오버 피팅을 해결하기 위해서 1. training data를 더욱 늘리거나 2. feature(x 변수)를 줄이거나 (이 방법은 굳이 사용하지 않아도 괜찮다.) 3. Regularization(정규화)를 진행해 모델의 하이퍼플레인(선)을 보다 평탄하게 해주는 방법이 있다. (= 가중치에 너무 큰 값을 배정하지 않게 하자!)
# 드롭아웃 (Dropout)
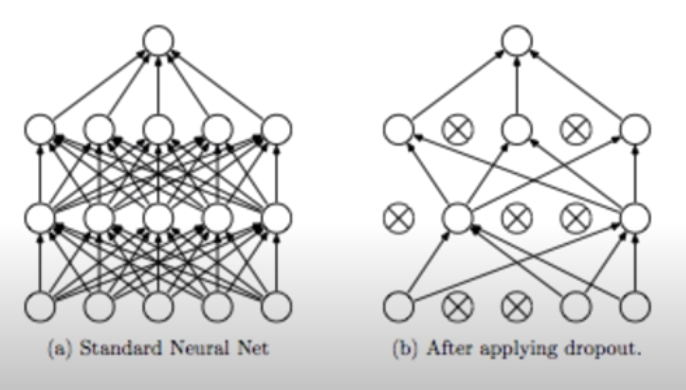
그러나 뉴럴넷 모델이 복잡해지면 정규화만으로 오버피팅에 대응하기 어려워지는데, 이 때 Dropout 기법이 사용된다. Dropout: A Simple Way to Prevent Neural Networks from Overfitting (Nitish Srivastava et al. 2014) 논문에 따르면 Dropout은 랜덤하게 어떤 뉴런들의 연결을 끊고 해당 뉴런을 비활성화시켜 뉴럴넷을 보다 간소하게 만드는 방법이다. 힘들게 만든 뉴런들을 왜 없애는 지에 대한 강한 의문이 들 수 있지만, 이 방법은 생각보다 큰 성능 상승 효과를 가져온다.

각 뉴런들은 각자 한 분야의 전문가 역할을 한다. 예를 들어, 고양이인지 아닌지 판단하는 뉴럴 넷을 사용한다고 할 때, 어떤 뉴런은 귀를 갖고 있는지 아닌지 판단하는 전문가, 어떤 뉴런은 꼬리를 가지고 있는지 판별하는 전문가, 어떤 뉴런은 털이 있는지 없는지 판단하는 전문가이다. 이런 뉴런들 중 몇몇을 쉬게 하여 학습을 진행하는 것이 Dropout 방법이다.
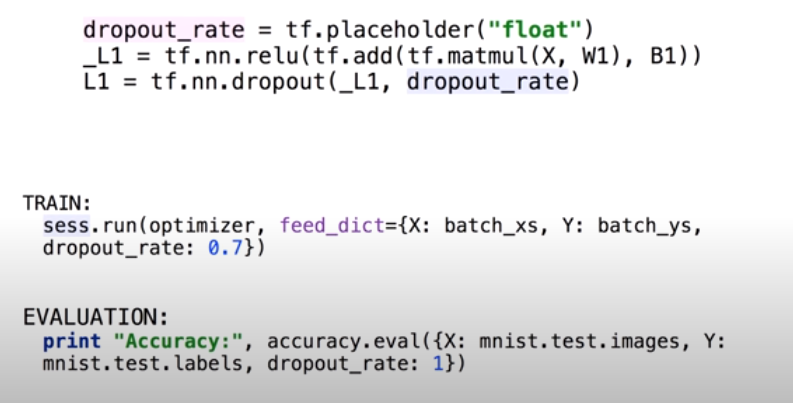
Dropout을 텐서플로우에서 적용하는 방법은 단순히 활성화 함수까지 있는 레이어에 Dropout 레이어를 하나 추가해주는 것이다. 이 때 dropout_rate를 설정해줘야 하는데, 보통 0.5로 설정하여 매 레이어마다 랜덤하게 학습하는 뉴런을 다르게 한다. Dropout에서 주의할 점은 training할 때만 적용해야 한다는 점이다. 학습시킬 때는 Dropout으로 랜덤하게 뉴런들을 학습시키고 test할 때는 dropout없이 모든 뉴런을 사용해서 예측해야 한다.
# 앙상블 (Ensemble)

모델의 성능을 높이는 방법 중 하나로 앙상블(Ensemble) 기법이 있다. 예를들어, 위 그림과 유사하게 9개의 층을 가진 신경망 모델이 k개 있다고 하면, 이를 각각 모두 학습시킨 후 예측한 결과들을 마지막에 통합하여 최종적인 예측 결과를 도출할 수 있다. 마치 여러 전문가에게 의견을 물은 후 투표를 통해 최종적인 결론을 내리는 것과 유사한 이 방법은 적게는 2%에서 많게는 4~5%까지 모델의 성능을 향상시킨다.
본 포스팅은 김성훈 교수님의 강의
'모두를 위한 딥러닝'을 학습하고 정리한 내용을 담고 있습니다.
'AI > 모두를 위한 딥러닝' 카테고리의 다른 글
[모두를 위한 딥러닝] 12. RNN (Recurrent Neural Network) (0) 2020.12.11 [모두를 위한 딥러닝] 11. CNN (Convolutional Neural Network) (0) 2020.12.09 [모두를 위한 딥러닝] 10-2. Weight initialization (0) 2020.12.08 [모두를 위한 딥러닝] 10-1. ReLU 함수 (0) 2020.12.07 [모두를 위한 딥러닝] 9. 딥러닝으로 XOR 문제 풀기 (0) 2020.12.02